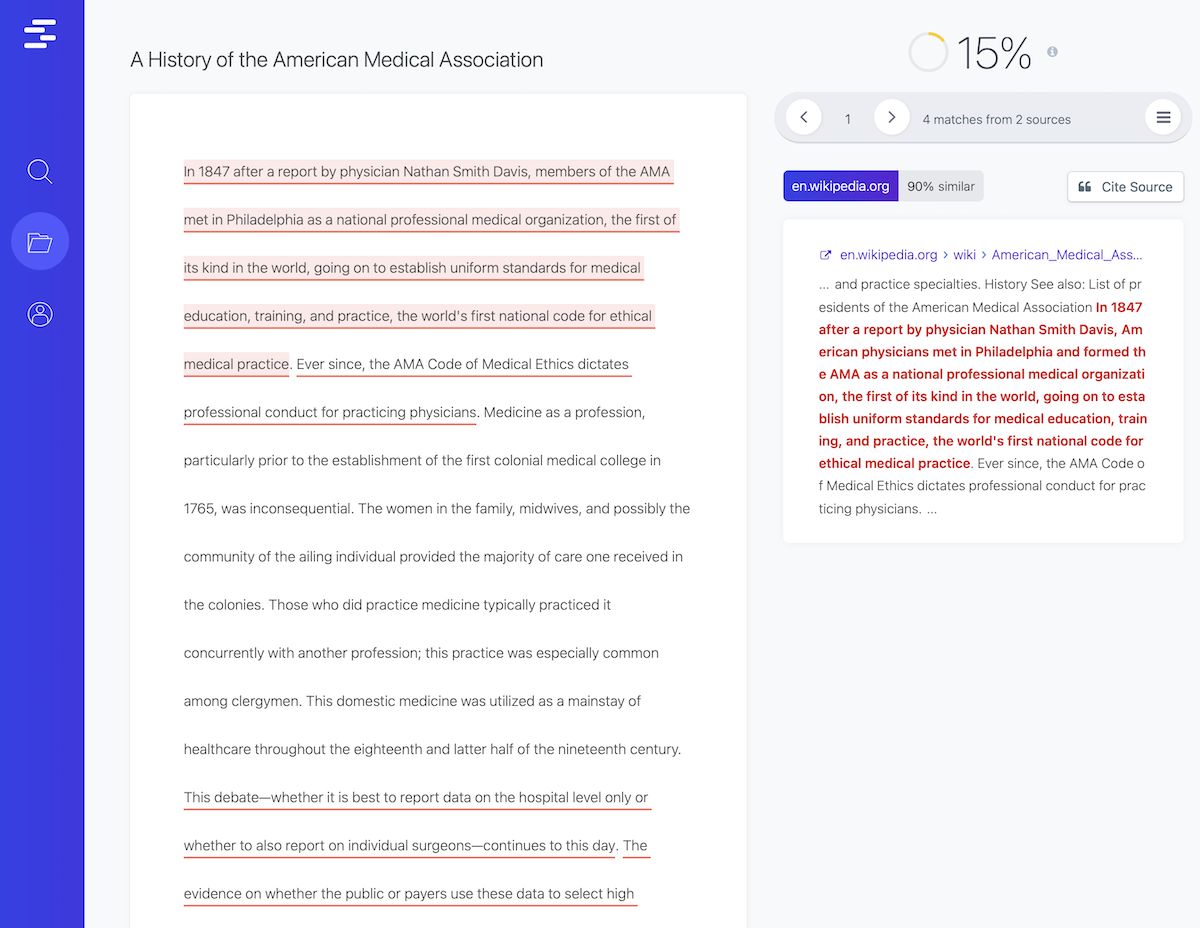
DeepSearch™ goes beyond simple word matching; taking into account the surrounding context and the statistical likelihood of each word and phrase.
Our algorithms use state-of-the-art natural language processing to detect "fuzzy" matches, where several words have been changed in an attempt to disguise plagiarism.
Fuzzy scoring calculates a conditional score, meaning that we not only factor your DeepSearch™ total score, but each match is also weighted individually in the context of the whole.
Our proprietary technology helps us detect similarities in a way that only Quetext does.

Custom built with state-of-the-art machine learning & grammatical analysis techniques.
Our in-house technology uses innovative algorithms to quickly search across billions of documents, while still maintaining a robust and expansive search.


Don't risk it with those 'free' plagiarism checkers designed solely to mislead you for ad-revenue. Protect your writing with technology designed by people who care!
We work to provide the most advanced features available to help make preventing plagiarism painless (maybe even enjoyable)!
DeepSearch™
ColorGrade™ Feedback
Remarks
Citation Assistant
Originality Report
Interactive Snippet Text
Source Exclusion
Combined with our Plagiarism Assistant and Interactive Snippet Text, ColorGrade™ helps to make spotting and removing plagiarism intuitive and fast!
Try it Now!